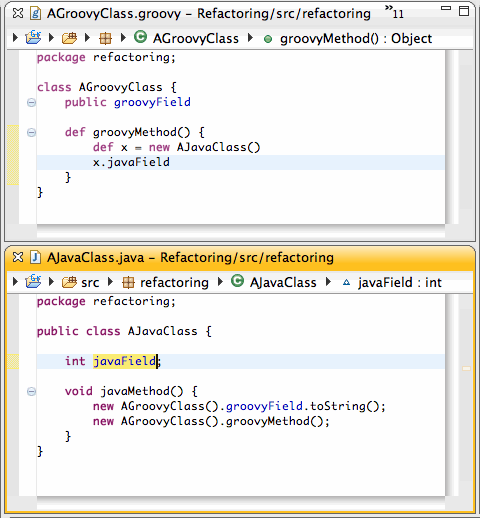
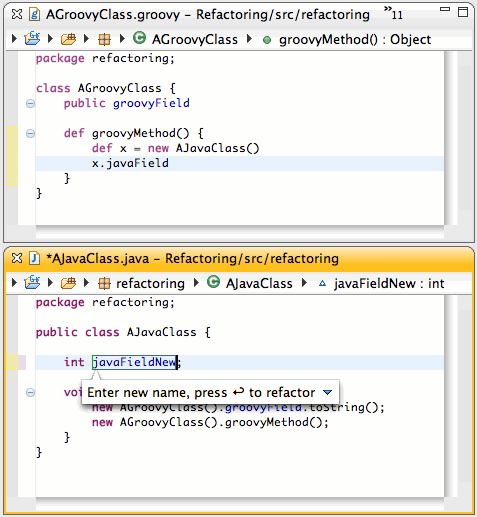
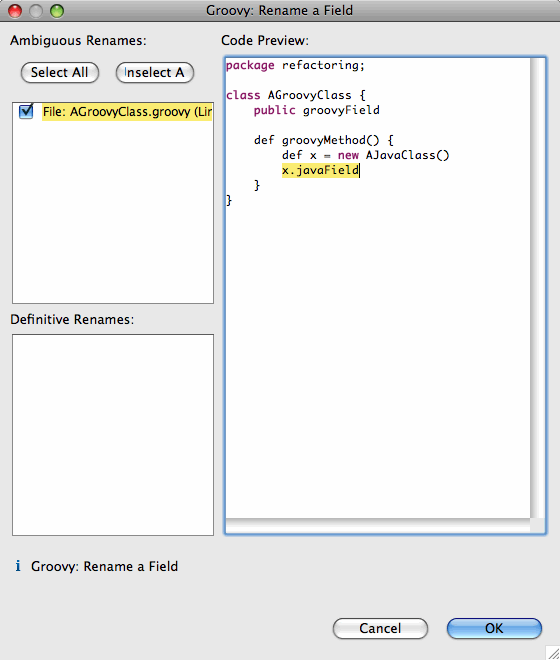
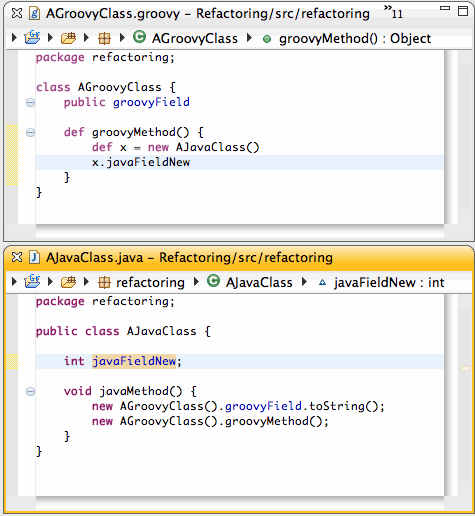
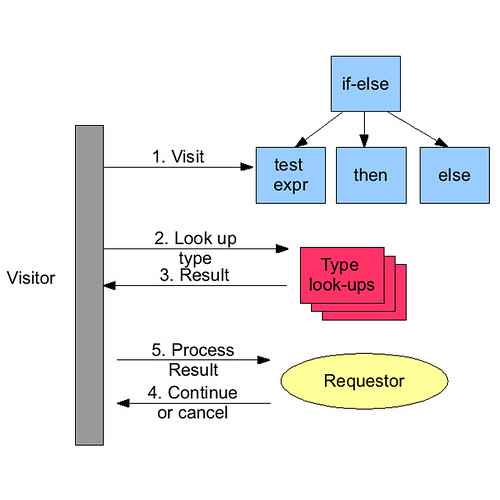
We provide three extension points, one for adding new smarts to the inferencing engine: one for adding new content assist proposals, and one for adding new highlighting rules to the editor.
Extending Syntax Highlighting
The simplest way to extend Groovy-Eclipse is through the org.codehaus.groovy.eclipse.ui.syntaxHighlightingExtension extension point.
Here is what STS does to use the extension point:
<extension
point="org.codehaus.groovy.eclipse.ui.syntaxHighlightingExtension">
<highlightingExtender
extender="com.springsource.sts.grails.editor.groovy.GrailsSyntaxHighlighting"
natureID="com.springsource.sts.grails.core.nature">
</highlightingExtender>
</extension>
As you can see, an extender class (com.springsource.sts.grails.editor.groovy.GrailsSyntaxHighlighting) is associated with a project nature (com.springsource.sts.grails.core.nature). And now, whenever a Groovy Editor is opened for a Grails project, all of the syntax highlighting rules from the extender class is added to the Groovy Editor. For Grails, the extension is simple:
public class GrailsSyntaxHighlighting implements IHighlightingExtender {
public List getAdditionalGJDKKeywords() {
return Arrays.asList(
// domain fields
"constraints", "belongsTo", "hasMany", "nullable", "belongsTo", "mapping",
"hasMany", "embedded", "transients", "id", "tablePerHierarchy", "version",
// domain methods
"list", "save", "delete", "get",
// controller fields
"log", "actionName", "actionUri", "controllerName", "controllerUri",
"flash", "log", "params", "request", "response", "session",
"servletContext",
// controller methods
"render", "redirect"
);
}
public List getAdditionalRules() {
return null;
}
public List getAdditionalGroovyKeywords() {
return null;
}
} New GJDK keywords are added and nothing else. Also, note that GrailsSyntaxHighlighting implements IHighlightingExtender. And here is what the additional syntax highlighting can give you:

Notice that the special Grails domain class fields such as belongsTo and mapping are highlighted, and below in the controller class, keywords like params and render are highlighted.
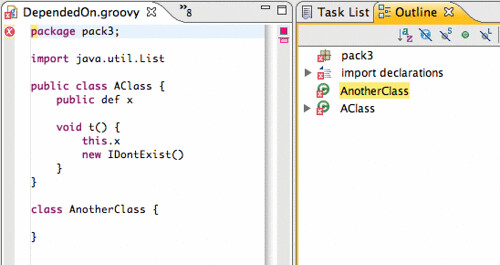
Extending the inferencing engine
The Groovy-Eclipse inferencing engine is used to infer the types of expressions within a Groovy file. Because of its dynamic nature, determining the types of all Groovy expressions in a file is undecidable. The good news is that most programs are well-behaved and follow a simple set of rules through which we can infer the types of most expressions. Meta-programming in Groovy can add new members to Groovy objects and classes. This is a feature used by most Groovy DSLs.
Groovy-Eclipse allows DSL programmers to specify the meta-programming through the org.eclipse.jdt.groovy.core.typeLookup extension point. Here is what the extension point looks like in the Grails tool support in STS:
<extension
point="org.eclipse.jdt.groovy.core.typeLookup">
<lookup lookup="com.springsource.sts.grails.editor.groovy.types.GrailsTypeLookup">
<appliesTo projectNature="com.springsource.sts.grails.core.nature"/>
</lookup>
</extension>
Here the class com.springsource.sts.grails.editor.groovy.types.GrailsTypeLookup is defined to be a type lookup for projects that have the com.springsource.sts.grails.core.nature (i.e., this lookup is only activated for Grails projects).
Let's take a look at the GrailsTypeLookup class:
public class GrailsTypeLookup extends AbstractSimplifiedTypeLookup implements ITypeLookup {
private IGrailsElement element;
private GrailsProject gp;
public void initialize(GroovyCompilationUnit unit,
VariableScope topLevelScope) {
gp = GrailsCore.get().getGrailsProjectFor(unit);
if (gp != null) {
element = gp.getGrailsElement(unit);
element.initializeTypeLookup(topLevelScope);
}
}
@Override
protected TypeAndDeclaration lookupTypeAndDeclaration(
ClassNode declaringType, String name, VariableScope scope) {
IGrailsElement declaringElt = gp.getGrailsElement(declaringType);
return declaringElt.lookupTypeAndDeclaration(declaringType, name, scope);
}
}According to the extension point specification, GrailsTypeLookup must extend ITypeLookup and we choose to let it extend AbstractSimplifiedTypeLookup in order to reduce the amount of coding required.
The initialize method is called when type inferencing is starting for a Groovy file. Here, it is possible to stuff things into the top level scope (such as global variables). For Grails, we determine what kind of Grails element we are performing inference on (e.g., a domain class, controller class, taglib, etc) and modify the top level scope appropriately.
More magic happens in the lookupTypeAndDeclaration method. Again, the type lookup delegates to the specific Grails element to determine what the type is.
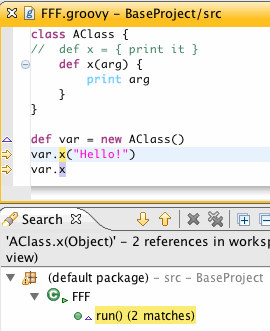
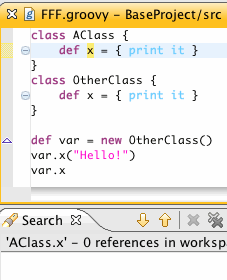
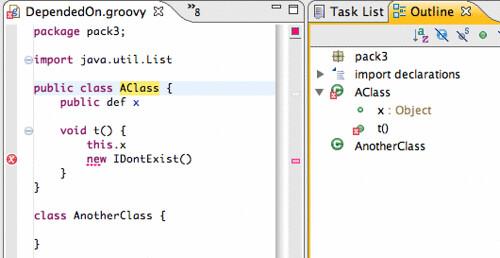
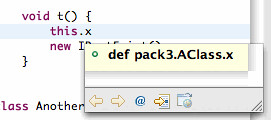
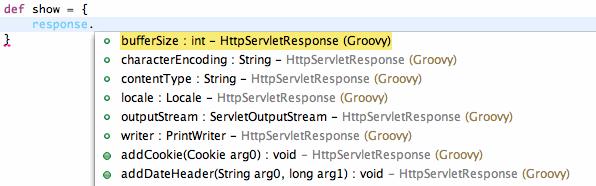
Now, let's take a look at what this can do for us. Notice that hovering over Grails keywords will bring up a JavaDoc of the inferred type of that keyword:

The Grails response field in controller classes is of type HttpServletResponse. Similarly, this allows us to get HttpServletResponse aware content assist proposals:
Extending Content Assist
The final step is to hook extensible content assist into the DSL. This can be tricky. For example, in Grails, there are certain fields that if defined have special meaning. There is the constraints field where constraints for domain classes are defined, and the mapping field where object-relational mappings are defined. The closure attached to each of these fields have special keywords that they expect.
This is possible to control through the org.codehaus.groovy.eclipse.codeassist.completion.completionProposalProvider extension point. Here is how it is used in STS:
<extension
point="org.codehaus.groovy.eclipse.codeassist.completion.completionProposalProvider">
<proposalProvider
proposalProvider=
"com.springsource.sts.grails.editor.groovy.contentassist.GrailsProposalProvider">
<appliesTo projectNature="com.springsource.sts.grails.core.nature"/>
</proposalProvider>
</extension>
This extension point wires a com.springsource.sts.grails.editor.groovy.contentassist.GrailsProposalProvider to the Grails project nature. And so (as with the other extension points), theis extra content logic will only occur when inside a Grails project.
com.springsource.sts.grails.editor.groovy.contentassist.GrailsProposalProvider implements org.codehaus.groovy.eclipse.codeassist.processors.IProposalProvider. This interface has three methods to implement:
- getNewFieldProposals: Return a list of fields that can be defined at the content assist location. For example, here is where all special fields available in Grails domain classes are proposed. This method is only called when content assist is invoked when inside a class body (i.e., only where it is appropriate to define new fields).
- getNewMethodProposals: Return a list of new methods that can be defined at the invocation location. As with the new fields method, this method is only called when content assist is invoked in a location that is possible to define new methods.
- getStatementAndExpressionProposals: This method returns all possible special content assist proposals when in the context of an expression or statement. For example, here is where special controller class fields like params, request, and response are inserted.
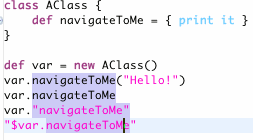
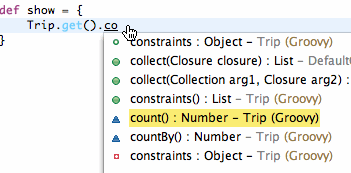
Let's take a look at what this can do. In this screenshot, you can see that when performing content assist on a reference to a Grails domain class, you can access Grails specific methods like count:
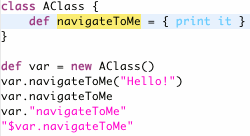
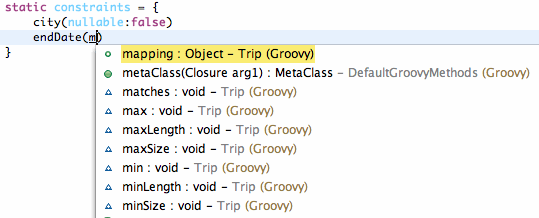
And when inside the constraints block (and only when within that block) content assist is augmented with possible constraints to add:
Conclusion
We have worked hard to make sure that Groovy-Eclipse is extensible. It is already being used by some DSLs such as EasyB and by BonitaSoft.
These extension points and APIs are still a work in progress if you have any questions, or require some changes to anything, please raise a bug or send a message to the mailing list.