http://dist.codehaus.org/groovy/distributions/greclipse/snapshot/e3.5
In this post, I am going to describe how the inferencing engine is currently used in Groovy-Eclipse and then I will dive a deep and describe how it is implemented. I'll end the post by describing our plans for immediate the future.
What type inferencing is used for
Underlining statically indeterminate references
The Groovy editor now underlines all references that cannot be determined while editing. This happens in a background thread while you type. So, the following code (notice the mispelling of asImmutable):
def aList = []
def otherList = aList.asImmutabl()
otherList.asImmutable()
...will appear in the editor like this...
...and when the typo is fixed, the underlines go away...
Code is re-analyzed after every keystroke (well, actually, it is after every keystroke that is followed by 500ms of no keystrokes). The type of every reference in the file is looked up using the inferencing engine. Every reference that cannot be found is considered to be unknown and will be underlined.
Of course, Groovy being a dynamic language, not all references can be statically linked to a type (other than Object). This is especially the case when working with DSLs (such as Grails) that use metaprogramming to add new methods and fields to existing types. Later, I'll describe our plans for extensibility.
Search
Inferencing is used for Java Search as well. Using the search short cut (CTRL-Shift-G or CMD-Shift-G on Mac) or running search from the Java Search dialog, references from and to Groovy code snippets can be located. However, there are some difficulties here. Compared to Java, Groovy is quite a bit more flexible in the ways that fields and methods can be referenced. For example, this field is assigned a closure and referenced as if it were a method:
class Foo {
def x = { print it }
}
x("Hello!")
And this method is referenced in a way that is statically indistinguishable from a field:
class Foo {
def x() { print "Hello!" }
}
x
Furthermore, the spread operator and the use of default parameters makes the Java way of determining which method or field is referenced impossible. So, Groovy search is significantly more liberal than Java search in what it considers a search match. If a reference corresponds to any field, method, or property in the declaring type (regardless of parameter count and whether it is accessed as a field or method), then the match is considered successful. This leads to the following scenarios.
1. Performing search on the field declaration finds field references here:
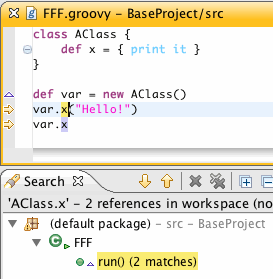
2. Performing search on the method declaration finds exactly the same references:
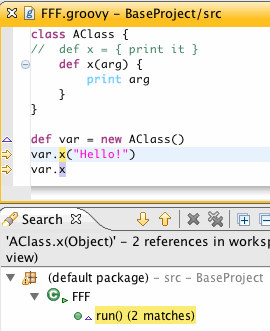
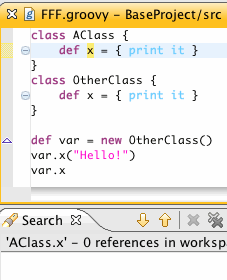
And, notice that references attached to the wrong type are not considered a match.
Content Assist
Most of the internals of Groovy-Eclipse has been rewritten since the previous 1.5.7 release. The most recent rewrite is of content assist. Although the previous version worked (usually), there was always a noticeable lag while waiting for the content assist window to appear. This previous implementation of content assist used a combination of Java classloading and Groovy AST matching in order to find all completion proposals available at a given location, which was both messy and slow. Now, we have hooked into the inferencing engine and have completely rewritten proposal generation with extensibility in mind. And we have made some remarkable improvements in performance.
Using the following code snippet I performed content assist 5 times under the old implementation and the new and took the average of the last 3 of each:
def x
x.hasProperty("foo").
| Old implementation | 2315 milliseconds |
| New implementation | 8 milliseconds |
That's right...there is a 3 orders of magnitude speed up under the new implementation, making content assist a much more pleasant feature to use. But please note that this is just the time for calculation of the proposals and it does not include the time required to actually pop up the window.
Open declaration
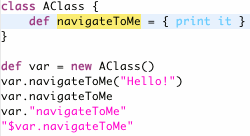
The implementation of open declaration (or code select as it is called in JDT because it is a general mechanism to determine what the current selection refers to and is also used for things like calculating hovers) also uses inferencing. Pressing F3 whenever the selection is any form of "navigateToMe" in the following code, the expected declaration will open:
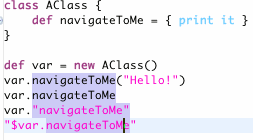 --->
---> 
Although Groovy-Eclipse M1 used type inferencing for code select, it was using the inferencing from content assist and was subject to the same mistakes, duplicate answers, and slowness that content assist had.
How it works
The inferencing engine has unified the implementation of several of Groovy-Eclipse's most widely used features. With this unification, we have been able to significantly reduce the amount of duplicated code, improve performance, and plan for extensibility.
There are four interacting components of the inferencing engine:
- The Abstract Syntax Tree (or AST): this is an abstract representation of the syntax of a groovy file expressed hierarchically. The code to work on can be obtained either from the disk, or it can be the latest in memory. The AST is generated by the Groovy compiler based on the current state of the editor whenever Eclipse is otherwise idle.
- The type inferencing visitor: this visitor walks the AST (i.e., uses a visitor pattern to visit every AST node) and delegates to the type lookups and the requestor described below. A new visitor is created for each call to the inferencing engine.
- The type lookups: these objects lookup the type information of a particular expression using whatever mechanism they require. They can store and retrieve information about types in a way that all other lookups can use. In this way, each lookup can do what it can and coordinate with other lookups where required. Several default lookups are provided including a simple lookup, an inferencing lookup (that stores information about types via assignment expressions), and a category lookup (that looks up types in Groovy categories). Type lookups are created from a registry on each call to the inferencing engine.
- The requestor: this is the object that collects the type information determined by the lookups. The requestor is general and can be used as a way to store the types of all expressions, lookup the type of a particular expression, or look for expressions with unknown types (just to name a few uses). The requestor is created by client code and past to the visitor to start the inferencing process.
The following diagram shows process and how the different pieces work together:
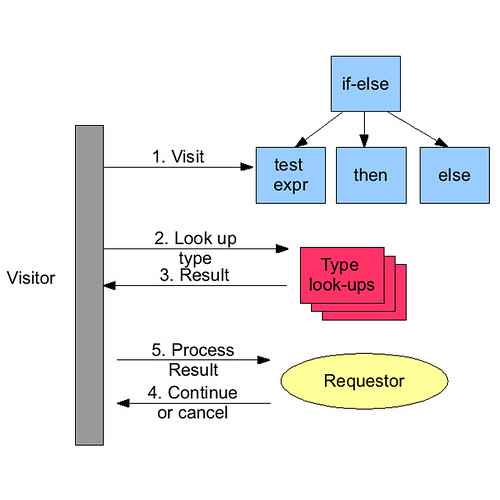
- The visitor visits an AST expression node
- The visitor sends this expression to the type lookups.
- each lookup responds with a type and its confidence in that type (ie, exact, potential, inferred...), or null, if it cannot find a type
- a lookup may additionally store information in a scope object that is passed around to other lookups so that information can be shared between them
- The result of the lookup is sent to the requestor
- The requestor processes the result and may choose to end the visit or continue.
- If required, the visitor will continue to visit the rest of the abstract syntax of the Groovy file
What's next
One of the core design goals of the inferencing engine is extensibility. The inferencing engine must be extensible in two ways. First, it must be usable to help support new features such as quick fixes and refactoring. Also, DSLs, (most notably Grails) must be able to extend inferencing with their own type lookups. It should be apparent through the description of the variety of ways that the engine is currently used that it versatile and can become the core implementation of any number of new Groovy-Eclipse features. As for DSL extensibility, that has not yet been implemented, but the stubs are available. Other DSLs will need to implement their own type lookup, but there is currently no way for these new lookups to be plugged in. Fortunately, it will be possible to use Eclipse's plugin architecture here and this will be the subject of my next blog post (after it gets implemented).
Cool post and awesome changes/additions to the plug-in. Thanks!
ReplyDeleteBy the way, I noticed a small mistake early in the post. I'm guessing that the second image was supposed to be different from the first. ;)
--Matt
Ha! Thanks, Matt. Fixed now.
ReplyDeleteThis means I can turn on time-delay content assist! I had to disable it from automatically kicking in due to the time lag of response. Awesome!
ReplyDelete